Build a Private Knowledge Base with LangChain + RAG (Full Tutorial with Code)
Retrieval-Augmented Generation (RAG) is a powerful framework that allows you to ask questions over your own documents using a Large Language Model (LLM). In this post, we’ll walk through how to use LangChain to build a RAG system—from loading PDFs to querying your data—with code and a visual workflow.
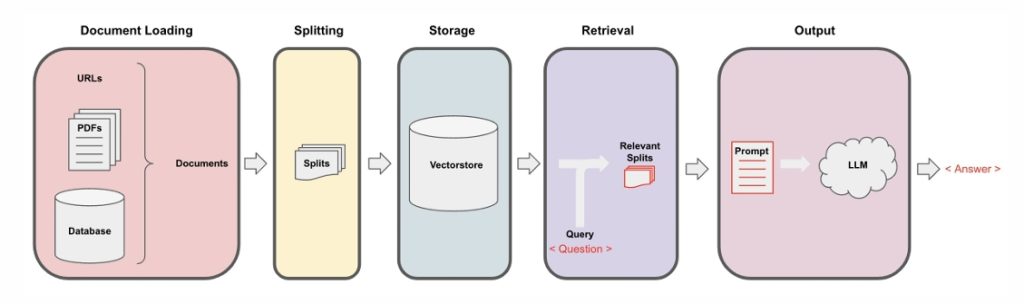
Step-by-Step Implementation in LangChain
1. Document Loading
LangChain supports many loaders: PDFs, text files, URLs, even YouTube transcripts.
from langchain.document_loaders import TextLoader
loader = TextLoader("./data/email.txt")
documents = loader.load()Tip: You can switch to PyPDFLoader, UnstructuredURLLoader, or others depending on your data source.
2. Chunking Documents
Long documents are broken into smaller chunks for better embedding and retrieval.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
splits = text_splitter.split_documents(documents)Why? Chunking preserves context and improves matching relevance.
3. Embedding & Vector Storage
Each chunk is converted to a vector and stored in a vector database like FAISS, Pinecone, or Weaviate.
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embedding)4. Retrieval
This allows semantic search over your data using user queries.
retriever = vectorstore.as_retriever()
query = "What did the email say about the product launch?"
relevant_docs = retriever.get_relevant_documents(query)5. LLM Response Generation
The final step: retrieved chunks are sent to a language model to generate an answer.
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.run(input_documents=relevant_docs, question=query)
print(response)Full Pipeline Recap
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
loader = TextLoader("./data/email.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
splits = text_splitter.split_documents(documents)
embedding = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embedding)
retriever = vectorstore.as_retriever()
query = "What did the email say about the product launch?"
docs = retriever.get_relevant_documents(query)
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.run(input_documents=docs, question=query)
print(response)Final Thoughts
LangChain makes it surprisingly easy to build an AI system that can answer questions using your own documents—a game-changer for business intelligence, legal research, customer support, and more.
- ✅ Control your data privacy
- ✅ Build custom GPT-like tools
- ✅ Integrate with Notion, websites, PDFs, etc.
If you’d like a web app version using Streamlit or Flask, or a WordPress plugin that lets users upload and query documents directly—just reach out!
1. Document Loading
LangChain supports many loaders: PDFs, text files, URLs, even YouTube transcripts.
from langchain.document_loaders import TextLoader
loader = TextLoader("./data/email.txt")
documents = loader.load() Tip: You can switch to PyPDFLoader, UnstructuredURLLoader, or others depending on your data source.
2. Chunking Documents
Long documents are broken into smaller chunks for better embedding and retrieval.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
splits = text_splitter.split_documents(documents)Why? Chunking preserves context and improves matching relevance.
3. Embedding & Vector Storage
Each chunk is converted to a vector and stored in a vector database like FAISS, Pinecone, or Weaviate.
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embedding)4. Retrieval
This allows semantic search over your data using user queries.
retriever = vectorstore.as_retriever()
query = "What did the email say about the product launch?"
relevant_docs = retriever.get_relevant_documents(query)5. LLM Response Generation
The final step: retrieved chunks are sent to a language model to generate an answer.
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.run(input_documents=relevant_docs, question=query)
print(response)Full Pipeline Recap
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
loader = TextLoader("./data/email.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
splits = text_splitter.split_documents(documents)
embedding = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embedding)
retriever = vectorstore.as_retriever()
query = "What did the email say about the product launch?"
docs = retriever.get_relevant_documents(query)
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.run(input_documents=docs, question=query)
print(response)Final Thoughts
LangChain makes it surprisingly easy to build an AI system that can answer questions using your own documents—a game-changer for business intelligence, legal research, customer support, and more.
- Control your data privacy
- Build custom GPT-like tools
- Integrate with Notion, websites, PDFs, etc.
Leave a Reply